
📊 Full opportunity report: VigilSAR Benchmark: There Is No Best Model on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The VigilSAR Benchmark shows no single AI model is best for all defense-related tasks. Rankings vary based on user needs, highlighting the importance of context in model selection.
The VigilSAR Benchmark has publicly released its initial findings, confirming that there is no single ‘best’ AI model for defense-related applications. Instead, model rankings vary significantly depending on the specific needs and profiles of different users, such as cloud providers, sovereign agencies, or compliance-focused organizations. This challenges the common perception driven by capability leaderboards that the most powerful model is automatically the best choice for deployment.
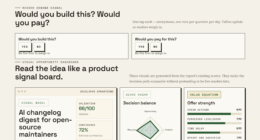
The VigilSAR Benchmark evaluates AI models across five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability. It scores models in eight knowledge domains relevant to defense, explicitly excluding harmful capabilities like weaponization, targeting, or exploit generation. The benchmark’s unique feature is its ability to re-rank models based on different buyer profiles, such as cloud-centric or sovereign, revealing that the top-ranked model varies according to the specific deployment context.
According to the developers, this approach emphasizes that a model’s suitability depends on more than just raw intelligence. For example, a highly capable model that cannot run on-premises or fails compliance checks would be unsuitable for certain defense applications. Conversely, a reliable, compliant, and deployable model might rank lower in pure capability but be more practical for specific environments. The initial results underscore that no single model dominates across all axes and profiles, reinforcing the importance of tailored evaluation.
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Why Model Contexts Trump Capability Rankings
This development matters because it shifts the focus from chasing the top capability scores to considering the practical deployment needs of defense and intelligence agencies. It highlights that models must be evaluated on trustworthiness, compliance, and deployability, especially in regulated or sensitive environments. The findings suggest that organizations should adopt a more nuanced approach to AI selection, avoiding reliance on capability leaderboards alone, which can be misleading and irrelevant for real-world use cases.
defense AI model evaluation tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Limitations of Traditional AI Leaderboards in Defense
Traditional AI benchmarks often emphasize raw performance on a set of tasks, leading to rankings that favor the most capable models. However, these leaderboards rarely address critical deployment considerations such as on-premises operation, compliance with EU regulations, robustness against adversarial inputs, and safety standards. The VigilSAR Benchmark was created to fill this gap by providing a multi-axial, context-aware evaluation tailored specifically to defense and intelligence needs. Its methodology is still evolving, and these initial results serve as a proof of concept rather than definitive rankings.
Prior to this, most model evaluations focused narrowly on capability, which can be misleading for organizations concerned with operational reliability and regulatory compliance. VigilSAR’s approach underscores that the ‘best’ model varies significantly depending on the specific environment and legal framework.
“There is no one-size-fits-all model. The right choice depends entirely on your specific needs and constraints.”
— Thorsten Meyer, lead developer of VigilSAR

Generative AI for Software Developers: Future-proof your career with AI-powered development and hands-on skills
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What Aspects of the Benchmark Are Still Developing
Since VigilSAR Benchmark is in early development, its methodology is subject to refinement. It is not yet clear how stable the rankings will be as the framework evolves, or how it will address emerging concerns such as new regulatory standards or adversarial threats. Additionally, the benchmark explicitly excludes certain capabilities like weaponization or exploit generation, focusing instead on legitimate defense-relevant knowledge, but how it will adapt to broader or more nuanced threat models remains to be seen.

AI Model Validation & Testing: Ensuring Reliable AI Systems — Bias Testing, Robustness Evaluation & Regulatory Compliance (AI Compliance Toolkit)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for VigilSAR Benchmark Development
The VigilSAR team plans to expand the benchmark’s scope, refine its scoring methodology, and incorporate more models and user profiles. Future updates are expected to include more comprehensive testing of robustness and safety, as well as wider adoption by defense and intelligence agencies. As the framework matures, it aims to become a standard reference for context-aware AI evaluation in regulated and mission-critical environments.

Machine Learning for High-Risk Applications: Approaches to Responsible AI
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is there no single ‘best’ AI model for defense?
Because the suitability of an AI model depends on specific deployment needs, such as compliance, operational environment, and robustness, rather than just raw capability scores.
How does VigilSAR Benchmark differ from traditional AI leaderboards?
It evaluates models across multiple axes relevant to defense, re-ranks them based on user profiles, and emphasizes trustworthiness and deployability over raw performance.
Can this benchmark help organizations choose the right AI model?
Yes, by providing a more nuanced, context-specific evaluation, it enables organizations to select models that best fit their operational and regulatory requirements.
Is the VigilSAR Benchmark final or still evolving?
It is still in early development, with ongoing refinements to its methodology and scope, and should be considered a work in progress.
Does the benchmark evaluate models for harmful capabilities?
No, it explicitly excludes assessments related to weaponization, targeting, or exploit generation, focusing instead on trustworthy, defense-relevant knowledge work.
Source: ThorstenMeyerAI.com