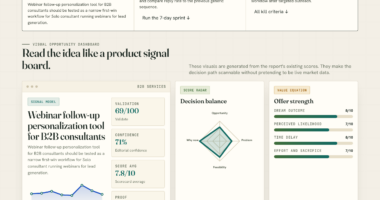
📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The AI industry faces a critical bottleneck: data scarcity and fencing. Verified human data now drives competitive advantage, with implications for startups and incumbents alike.
In 2026, the AI industry has shifted from freely scraping data to a model where access to high-quality, verified data is increasingly fenced, licensed, and protected by legal and industry barriers. This change makes data, rather than compute or algorithms, the primary chokepoint that determines competitive advantage, according to sources familiar with industry developments.
The industry has largely exhausted the free, public internet data for training models, with Epoch AI estimating that the public web holds roughly 300 trillion tokens of high-quality text. By 2028, this stock is projected to be fully utilized, pushing companies to seek verified, human-made data behind paywalls, inside enterprises, or in specialized domains.
Legal actions and settlements have marked the end of the era of free data scraping, as discussed in this analysis of recent AI industry legal developments. Notably, Anthropic settled a $1.5 billion copyright case in early 2026, with the court affirming that scraping copyrighted books without licensing was not protected as fair use. This has led to a market where data is now licensed, and access is often prohibitively expensive, favoring large incumbents and creating barriers for startups.
Meanwhile, the value of expertise has surged, especially in areas where AI-driven cyber threats are evolving rapidly. Training models now requires rare, expensive human input—lawyers, scientists, and domain specialists—whose authored data is costly but essential for high-quality outputs. Companies like Meta and Surge have invested heavily in expert-driven data, further consolidating industry power among those with resources to access and produce such data.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Why Data Fencing Shapes AI Industry Power
The shift to fencing and licensing high-quality data fundamentally alters the AI landscape. It consolidates power among large firms capable of paying for exclusive datasets and makes it harder for startups to compete. This change raises questions about innovation, access, and the future of open AI development, as data becomes a protected, market-driven resource rather than a freely available input.
verified human-made data for AI training
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
From Web Scraping to Data Fencing: Industry Evolution
Until 2025, AI training relied heavily on scraping the open web, with minimal legal barriers. However, landmark legal cases, such as Anthropic’s $1.5 billion settlement, signaled a turning point, establishing that scraping copyrighted material without licensing is not fair use. This legal precedent, coupled with industry moves towards licensing and paywalls, has transformed data into a guarded commodity.
Simultaneously, the nature of valuable data has shifted from generic web content to specialized, verified, human-generated information—expert annotations, battlefield footage, proprietary enterprise data—that cannot be easily replicated or bought. This evolution reflects a broader industry trend toward commoditization of compute and algorithms, with data becoming the remaining exclusive resource.
“The Anthropic settlement confirms that scraping copyrighted material without permission is no longer protected as fair use, setting a legal precedent.”
— Legal Expert

Understanding Open Source and Free Software Licensing
Used Book in Good Condition
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unclear Impact on Innovation and Smaller Players
It remains uncertain how smaller startups will adapt to the rising costs and legal barriers to data access. While large firms can afford licensing and expert data, the impact on innovation, open research, and democratization of AI development is still unfolding. The long-term effects of data fencing on industry diversity and breakthroughs are yet to be seen.
high-quality training data datasets
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in Data Market and Industry Consolidation
Industry analysts expect continued legal and market developments, including new licensing regimes, potential government regulation, and further consolidation among large players. Smaller firms may seek alternative strategies, such as synthetic data or proprietary data collection, but the cost barrier remains significant. Monitoring legal rulings and industry investments will be key to understanding the evolving data landscape.

Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data: 17th China National Conference, CCL 2018, and … (Lecture Notes in Artificial Intelligence)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
How does data fencing affect AI development?
Data fencing limits access to high-quality, verified data, favoring large, resource-rich companies and potentially slowing innovation among smaller startups.
What legal cases have influenced data access in AI?
The Anthropic copyright settlement in early 2026 is a landmark case affirming that scraping copyrighted works without licensing is not fair use, leading to increased licensing requirements.
Can synthetic data replace human-made data?
Synthetic data is increasingly used to supplement training, but it carries risks of errors and model collapse, making verified human data still essential for high-stakes domains.
Will open data sources remain relevant?
Open data sources are becoming less viable as legal and economic barriers rise, pushing the industry toward licensed, proprietary datasets.
What does this mean for AI innovation?
The increasing cost and scarcity of data could slow down innovation, especially for smaller players unable to afford licensing or expert data collection.
Source: ThorstenMeyerAI.com